徐々にPythonをいじりはじめましたが、何か作りたい物があるわけでもないのでとりあえずはWebスクレイピングの技術でも勉強しようかなと思っている所です。
Webスクレイピングとは、例えばどこかのショッピングサイトにアクセスして、1000円以下のスマホケースの値段データを取得してきたりするといったような技術の総称です。
まずその初期段階として、任意のサイトにアクセスして特定のタグ内の情報を取得するやり方を紹介します。
勉強のためにどんな動きをするか確認しながらいじっていたので必要の無いコメントアウトが多いですが、動きを理解するには役に立つと思います。
まずはアクセスして読み込みたいサイトの仮のデータを用意します。
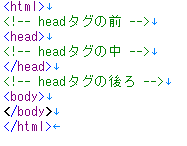
こんな最小限のHTMLを用意しました。
このHTMLにPythonでアクセスしてheadタグ内のデータを取得してみたいと思います。
<!-- headタグの中 -->
というデータが取得出来たら成功です。
ショボいように見えますが、私は知らない技術を勉強する時は最小限の動く物を作ってそこから膨らませていくというやり方をします。
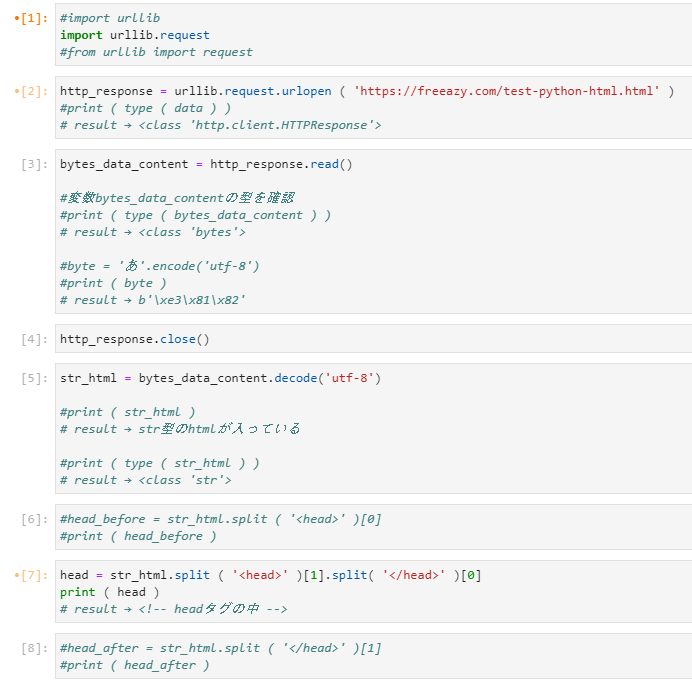
では、まず全体のコードの画像を貼り付けておきます。
では個別に見ていきます。
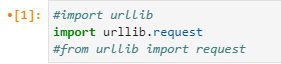
↑まずはサイトにアクセスしてデータを取得する動きをしてくれるライブラリーのurllibを呼び出します。
↓上2つの呼び出し方の場合次の行は以下のようになります。

が、3番目の from urllib import request という書き方をした場合は
↑赤線の部分の書き方が若干変わるので、ご注意下さい。

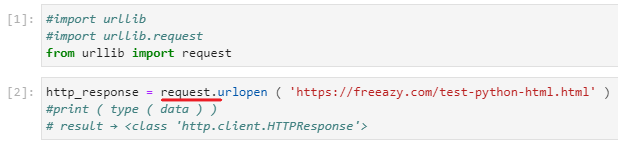
↑ここで開きたいサイトのURLを指定します。
戻ってくる型はhttp.client.HTTPResponseという型のデータが入ります。
※コメントアウトをはずすと確認できます。
このままでは中身が読めないので

↑read()というメソッドを使ってサイトにアクセスして戻ってきたデータをbytes型のデータに変換できます。
bytes型のデータのイメージを持ってもらうために「あ」という言葉をbytes型のデータに変換しました。
画像の一番下のようなものがbytes型のデータになります。
これではまだなんて書いてあるか人間には分かりませんね・・・。

親オブジェクトを削除します。
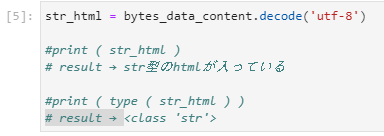
ここでbytes型のデータをデコードしてstring型の文字列にしています。
これで人間が読めるhtmlデータとなります。
↑ここからちょっとわかりづらくなるかもしれないので、丁寧に解説するために
取得したいHTMLデータをもう一度確認します。
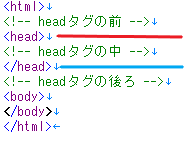
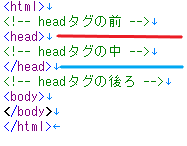
今回欲しいデータはheadタグ内のデータ(赤線と水色線の間のデータ)になります。
コメントアウトしてある <!--headタグの中--> という部分が取得したいデータになります。
↓そして、以下のコードはheadタグ内のデータ取得ではないのですが、わかりやすいように作りました。
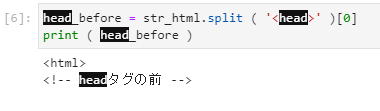
↑これはページ全体のHTMLの中の文字列からsplit関数を使って<head>で分けて0番目を取得するという意味になります。
つまり
↑赤線から上が取得できます。
赤線から下は
str_html.split ( '<head>' )[1]
となります。
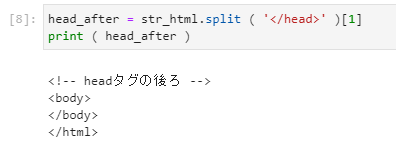
↑同じようにこれは</head>で分割して1番目を取得するという意味になります。
HTMLの画像でいうと、水色線から下を取得するという意味になります。
水色線から上は [0] になります。
0番1番と番号が増えていくのでご注意ください。
これらを踏まえて、
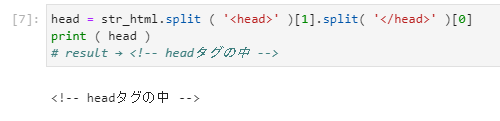
これを実行すると目的のheadタグの中身が取得できます。
1行で書いてるからわかりづらいですが、
head = str_html.split ( '<head>' )[1]
head = head.split ( '</head>' )[0]
print ( head )
これでも同じ意味になります。
head = str_html.split ( '<head>' )[1]
↑この行で赤線から下のHTMLがhead変数に入り、
head = head.split ( '</head>' )[0]
↑この行で水色線から上がhead変数にはいります。
結果headタグ内のデータだけが残ります。
※ 2行に分割する場合は2行目をstr_html.split から head.split に変える必要がありますので忘れないようにご注意下さい。
これで目的のheadタグ内のデータが取得できることになります。
最後の所がちょっとわかりづらい書き方かもしれませんが、順番に変数の中に何が入っているか確認していけばわかるかなと思います。
※コメントアウトしてある行は全てわかりやすいように付け足しただけで本来不必要なものになります。
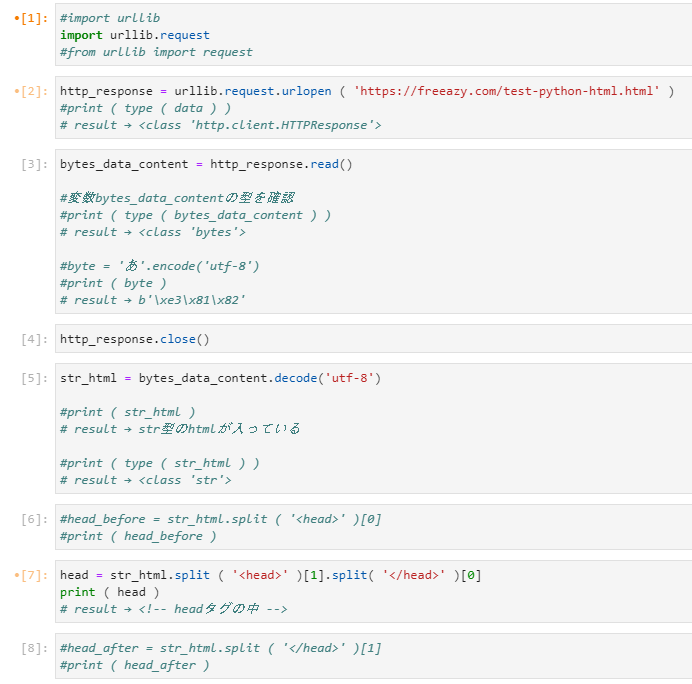
最後にもう一度全体のコードの画像を貼り付けておきます。